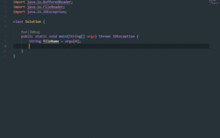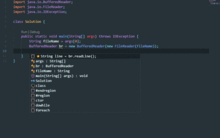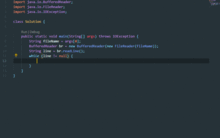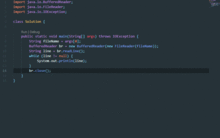
2023年國內人工智能軟件源碼加速迭代與快速上線開發指南
隨著2023年人工智能技術的持續爆發與深入落地,國內AI軟件開發領域正經歷一場以“快速迭代、敏捷上線”為核心的變革。高質量的AI軟件源碼更新與高效的開發流程,已成為企業搶占市場先機、實現技術商業化的關鍵。本文將探討2023年國內AI應用軟件源碼的發展趨勢,并提供一套助力快速上線的開發實踐指南。
一、2023年國內AI軟件源碼生態:開源與商業化并舉
2023年,國內AI軟件源碼生態呈現出前所未有的活力。一方面,以百度飛槳(PaddlePaddle)、華為昇思(MindSpore)、智源研究院等為代表的國產開源框架和模型庫持續更新迭代,提供了從基礎算法到預訓練模型的豐富、高質量源碼。例如,各類大語言模型(LLM)、計算機視覺(CV)模型的國產化開源版本不斷涌現,其代碼質量、文檔完善度和社區活躍度顯著提升,為開發者提供了堅實的“地基”。
另一方面,商業化AI解決方案提供商也紛紛開放或部分開放其核心模塊的SDK和API源碼,旨在構建開發者生態,加速行業應用落地。這些源碼通常更貼近特定行業場景(如金融風控、智能制造、智慧醫療),經過了實戰檢驗,能極大縮短企業從0到1的開發周期。
二、AI應用軟件開發新范式:基于成熟源碼的快速集成與微調
面對激烈的市場競爭,“快速上線”是硬道理。2023年AI應用開發的主流范式已從“從頭造輪子”轉向“基于成熟源碼的集成與微調”。
- 模塊化與組件化:優秀的AI源碼項目普遍采用高度模塊化的設計。開發者可以像搭積木一樣,選取所需的視覺識別、自然語言處理、語音合成、決策推理等模塊,通過清晰的接口進行快速集成。這要求開發團隊在前期選型時,必須評估源碼的架構清晰度、模塊解耦程度和接口規范性。
- 微調(Fine-tuning)成為標配:很少有AI模型能開箱即用地完美適應所有場景。利用開源或商業平臺提供的預訓練模型源碼,結合自身領域的標注數據進行微調,是快速獲得高性能定制化模型的核心路徑。2023年的工具鏈(如飛槳的PaddleHelix、MindSpore的Golden Stick)使得這一過程更加自動化和低代碼化。
- MLOps貫穿生命周期:快速上線不等于倉促交付。集成CI/CD(持續集成/持續部署)的MLOps理念被深度融入源碼工程實踐中。從數據管理、模型訓練、評估、部署到監控,全鏈路都有對應的開源工具(如國產的Alink、EasyML等)和最佳實踐源碼可供參考,確保AI應用能夠穩定、持續地迭代更新。
三、實戰路徑:從源碼獲取到快速上線的關鍵步驟
- 精準需求分析與源碼選型:明確業務場景與核心AI能力需求。在GitCode、Gitee、OpenI啟智等國內主流開源平臺,或各AI廠商的開發者社區,尋找匹配度高、近期有維護、社區活躍且許可證友好的項目。優先考慮帶有詳細文檔、示例代碼和基準測試報告的項目。
- 環境搭建與快速驗證:利用Docker等容器化技術,快速復現源碼項目提供的基準環境。運行其示例程序,驗證核心功能是否符合預期。這一步驟能有效評估源碼的可運行性和依賴管理的便利性。
- 核心業務邏輯集成與定制開發:將驗證通過的AI模塊作為服務(如通過封裝成RESTful API或gRPC服務)集成到自身業務系統中。在此階段,針對業務特有的邏輯和數據流進行定制開發。重點在于處理好業務數據與AI模型輸入輸出之間的適配與轉換。
- 數據準備與模型微調:收集和清洗自有業務數據,利用源碼提供的訓練/微調腳本,在預訓練模型基礎上進行優化。注意遵循數據安全與隱私保護法規。可使用自動化超參優化工具提升效率。
- 測試、部署與監控:進行全面的單元測試、集成測試和性能測試,特別是對AI模型的推理精度、速度、魯棒性進行嚴格評估。采用云原生技術(如Kubernetes)進行彈性部署。上線后,建立完善的模型性能與業務指標監控體系,為后續迭代提供依據。
四、挑戰與展望
盡管源碼資源日益豐富,開發者在快速上線的道路上仍需應對挑戰:如何確保所選源碼的技術前瞻性與長期可維護性;如何在集成多方源碼時解決潛在的兼容性與授權沖突;如何在小數據或敏感數據場景下有效進行模型優化等。
隨著國產AI基礎軟件的進一步成熟和AI開發平臺的普惠化,“低代碼/無代碼”AI開發將與源碼級深度定制更好地結合。開發者將能更聚焦于業務創新本身,利用持續更新的高質量AI源碼,將智能化應用的上市時間從“月”壓縮到“周”甚至“天”,真正釋放人工智能的生產力價值。
如若轉載,請注明出處:http://www.souplife.cn/product/41.html
更新時間:2026-01-21 00:48:47